
Open source vulnerabilities are increasing every year, not only because more and more organizations incorporate more and more open source into their software, but they’re also reporting it more frequently, as well:
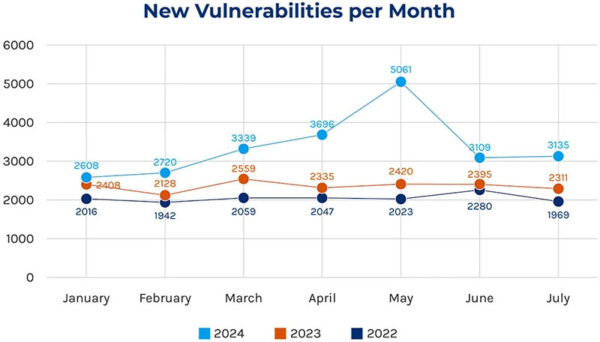
Source = Forescout’s 2024H1 Threat Review
This has led to a number of issues, not least of which was the US National Vulnerability Database (NVD) being overwhelmed earlier this year. If the US federal government can’t keep up with today’s threat landscape, what hope do the rest of us have?
The real problem is that vulnerability remediation is a moving target, with new vulnerabilities being found even as old ones get fixed. The process of investigating vulnerabilities, patching/upgrading, rebuilding your software, retesting, and redeploying simply takes far too long, but the process has remained essentially unchanged for decades despite the ever-growing volume of vulnerabilities.
But what if you could automate vulnerability remediation? Although it sounds like a Holy Grail, there are multiple initiatives underway to minimize the manual tasks that limit organizations’ ability to deal with vulnerabilities today. For example:
- Automating Investigation – reachability is a typical feature offered by SCA tool vendors. Essentially, the tool automatically performs a static analysis (e.g., at a minimum, to check if the affected module is loaded) or else a dynamic analysis (e.g., based on observations extracted from a running version of the target application) in order to check if your code actually makes use of the vulnerable part of the dependency.
While reachability isn’t perfect, it’s been a fairly common feature in SCA tools for many years, and continues to improve. Look for tools that offer dedicated analyses for each programming language, and/or cross-check static against dynamic analysis results.
- Automated Patching/ Upgrading – there are any number of tools that can identify vulnerable dependencies and notify you when a new version of that dependency (or a patch) has been released. GitHub’s Dependabot is a typical example.
But the real problem here is the lack of Semantic Versioning (SemVer) enforcement in open source ecosystems. Unfortunately, open source authors can – and do – introduce breaking changes in minor releases or even patches(!) rather than only in major versions. Patching/upgrading, then, is really the process of identifying whether breaking changes have been introduced, and refactoring your code, as appropriate.
While there are numerous AI-based tools that can help you refactor your code, they still make mistakes, hallucinate, and periodically lose context as their buffers fill up. In general, language-specific tools perform better than all-purpose ones, but it’s probably too early to rely on them as a completely automated solution.
- Automatically Rebuild, Retest and Redeploy – In theory, your CI/CD system takes care of this for you. In practice, code coverage is typically lacking, which limits the ability to automatically push to production with minimal risk. While there are AI tools that can help write unit tests to increase coverage, they suffer from the same problems as AI code refactoring tools.
It seems difficult to achieve automated vulnerability remediation without cutting a lot of corners at this point in time. But automation is central to ActiveState’s open source management platform, including when it comes to vulnerability remediation: i.e., enabling customers to automatically identify vulnerabilities and their upgrade targets, and then automatically rebuilding a fixed version of the runtime environment ready for test and deployment.
Streamlined Vulnerability Remediation
ActiveState has always provided the ability to identify vulnerable dependencies, as well as manually select an upgrade target, one by one. We are now introducing the ability to identify and upgrade vulnerable open source components at scale. We start by identifying the dependencies in all your projects (no matter where they’re deployed), and reporting on their vulnerability status:
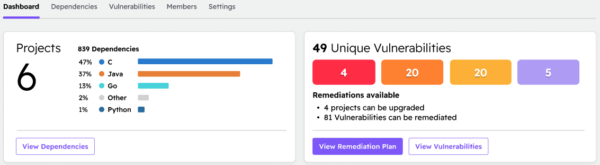
We then create a remediation plan to address the critical and high severity vulnerabilities that have a fixed version available:
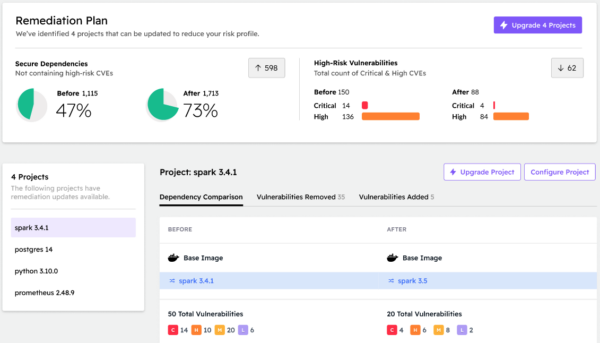
Clicking on each affected project in turn shows which vulnerabilities will be addressed. Because we continuously update our catalog of open source software from community repositories, we are able to identify whether an upstream vulnerability fix already exists (as shown in the screenshot above for spark), or whether a fixed version only exists for individual vulnerable components at this point in time. In either case, the ActiveState Platform will automatically rebuild the project in a few minutes for you, ready for testing:

The benefits are twofold:
- When an upstream fix doesn’t yet exist, ActiveState can still create a non-vulnerable version of your project by making updates at the component level, decreasing Mean Time To Remediation (MTTR).
- Projects are rebuilt automatically from vetted source code using our secure, hardened CI that can be seamlessly integrated with our existing CI/CD, speeding up your pipeline.
Note that after reviewing the proposed fixes, you could just as easily have chosen to fix all four projects at once, which would automatically rebuild all of them in parallel ready for testing, thereby dramatically reducing MTTR.
Conclusions – Automatically Manage Vulnerabilities
ActiveState’s solution offers the ability to automate the continuous discovery, tracking, and managing of all the open source in your organization from a single platform, including the ability to automatically remediate vulnerabilities at scale. All of which can provide you with a significant time, resource, and monetary advantage over managing multiple open source ecosystems using a variety of point solutions.
Automating vulnerability management is the only way for enterprises to keep up with the ever-accelerating number of vulnerabilities being discovered on a daily basis. While there are still gaps to close to ensure all stakeholders have the information they need to feel confident in an automated remediation solution, ActiveState’s collaborative open source management platform is designed to make everyone’s job easier, while decreasing the risks associated with vulnerabilities.
Next Steps
Interested in how you can automate your open source management tasks, including vulnerability remediation? Contact Us to see how it’s all possible via a single platform.




