





🎉 Introducing ActiveState Secure Containers and Container Customization—Learn More
You don’t need another scanner. You need a solution that acts on vulnerabilities for you.
“I don’t have to think too much about security and the complications anymore because ActiveState does it for me.”
– Stacy Leon, Sr. Technical Specialist
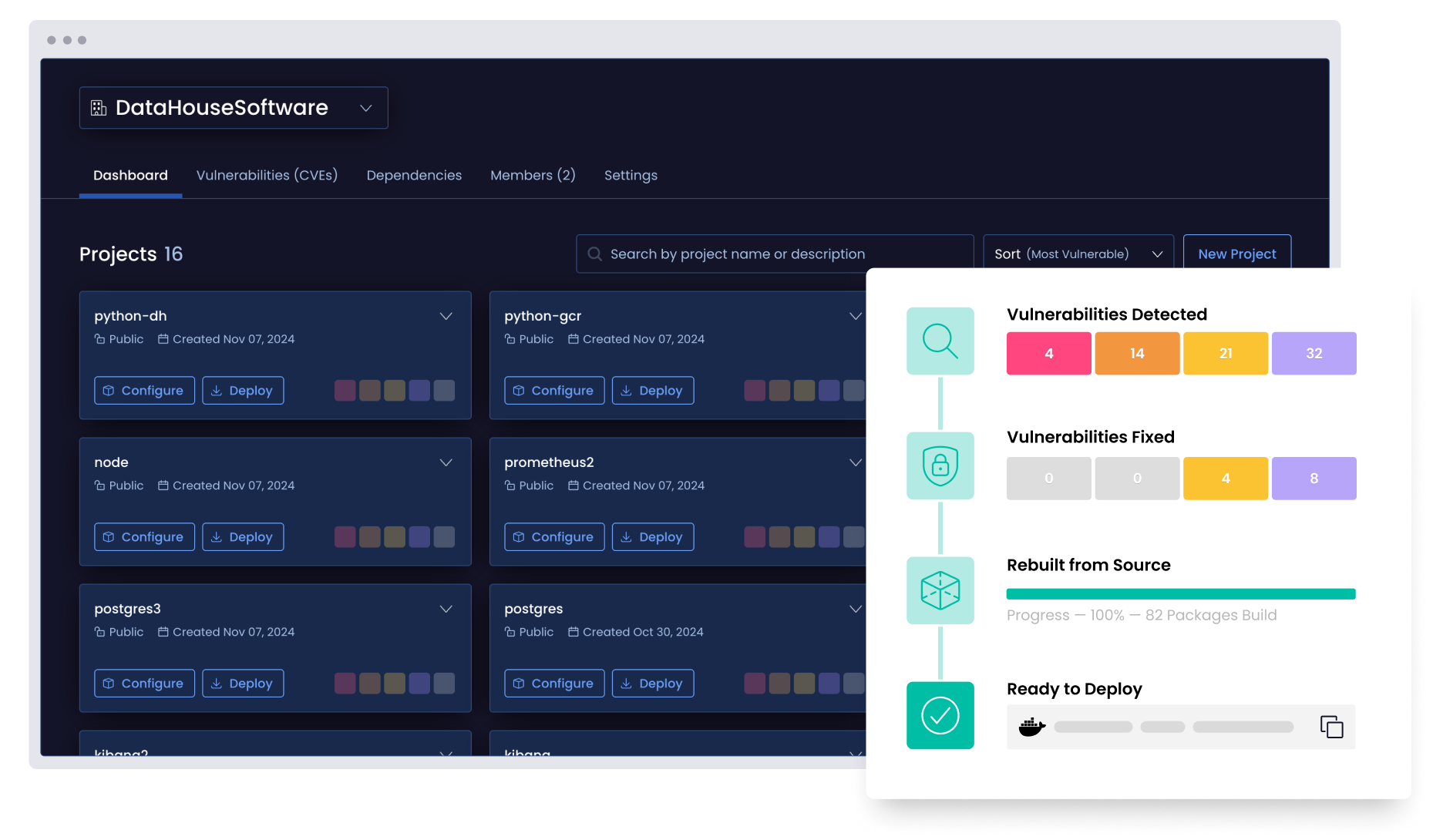
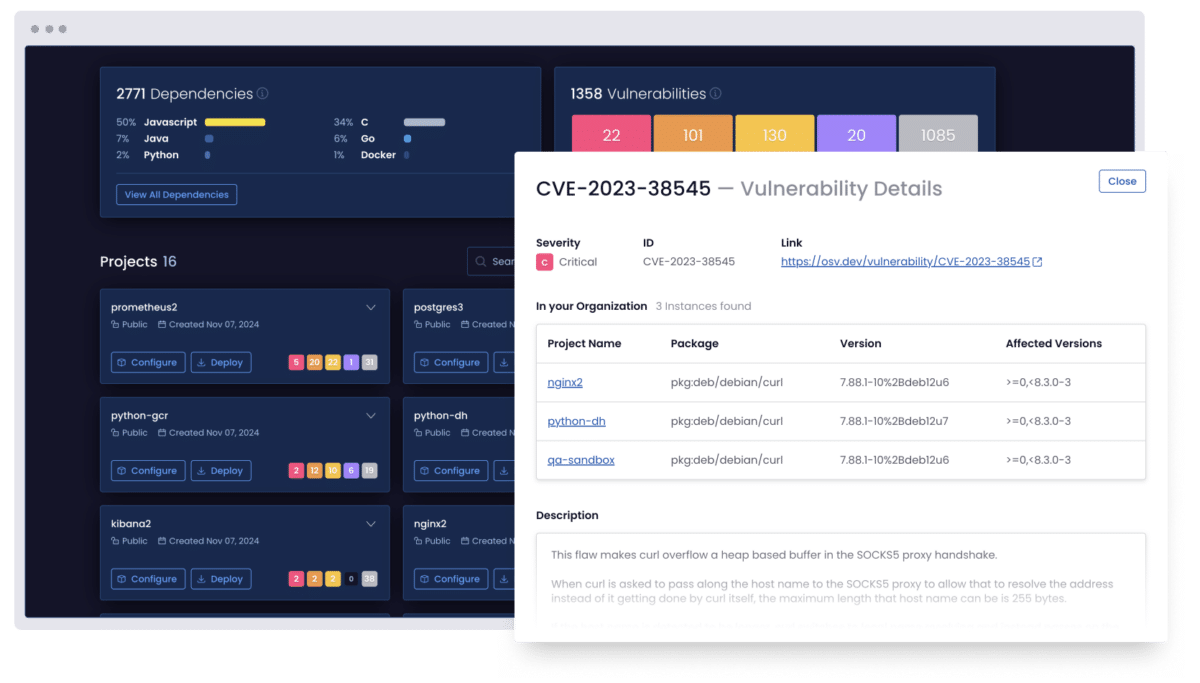
Reveal every vulnerability in your dependency graph, including transitive and nested issues. More importantly, visualize your vulnerabilities’ full blast radius.
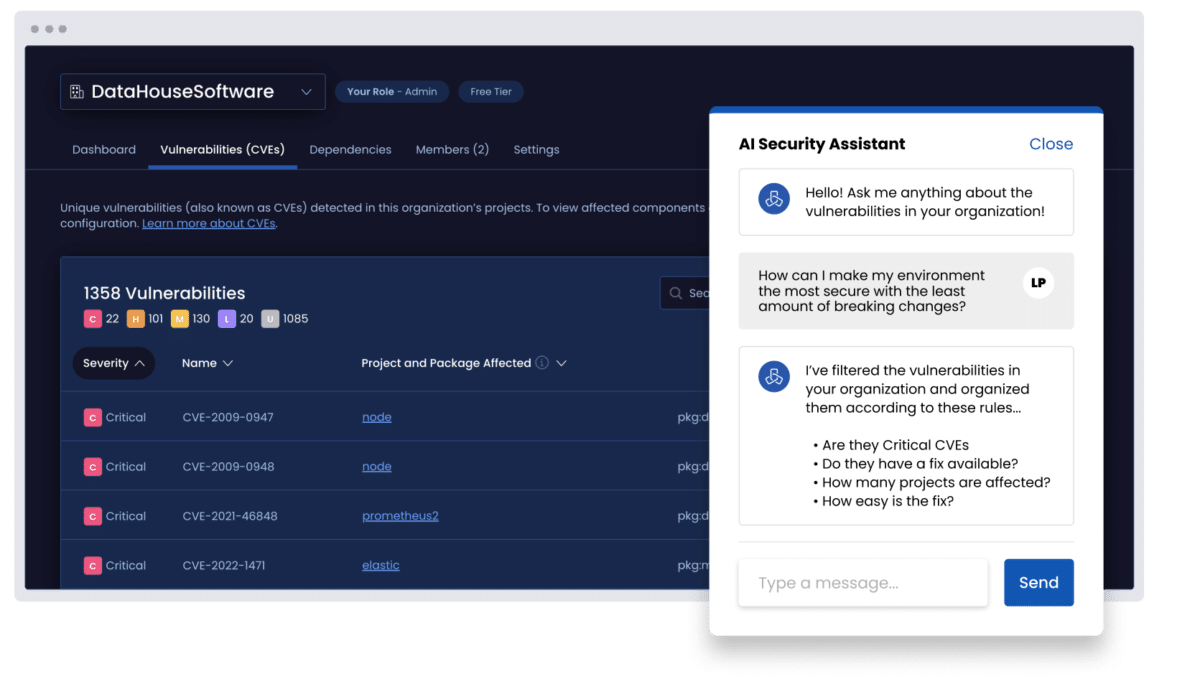
Our AI-powered engine evaluates exploitability, business impact, and breaking changes to capture only the risks worth your time.
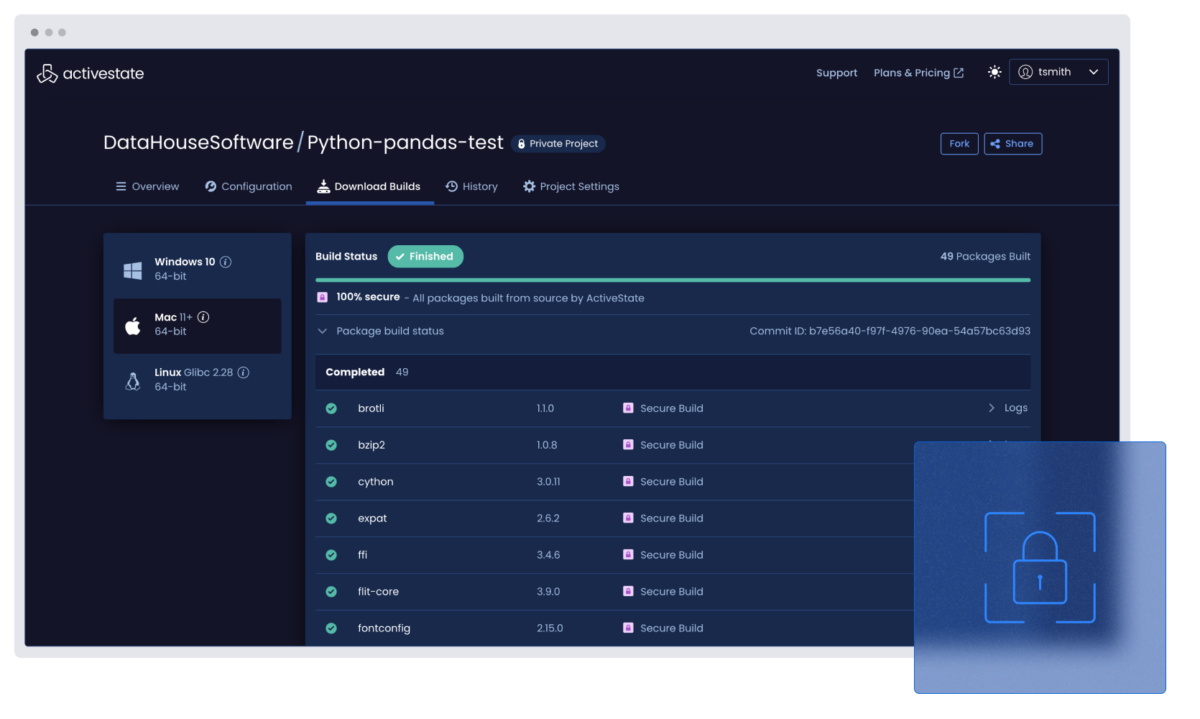
Secure fixes are applied directly within ActiveState using secure build best practices. No guesswork, and no regressions.
Find out how intelligent remediation helps you go beyond alerts and actually fixes open source vulnerabilities faster.
In your demo, you’ll learn how to:
Vulnerability scanners simply alert you after an application has been deployed. The ActiveState platform takes a preventative approach, and its vetted catalog of open source components helps block risky direct and transitive dependencies from entering your environment in the first place. It also digs deeper than most tools, analyzing down to the C library level to uncover issues others might miss.
Our AI evaluates exploitability, breaking change risk, and business impact so you can focus only on the vulnerabilities that actually matter.
The platform shows which projects are affected, how widespread a vulnerability is, and what impact remediation will have to your application, including potential breaking changes. It also estimates the effort required to fix each issue, helping you focus on vulnerabilities that pose the greatest risk with the least disruption.
Yes. The ActiveState platform applies secure fixes directly within your build pipeline. No need for external patching tools or developer guesswork!
Our Vulnerability Blast Radius feature maps each vulnerability across your full dependency graph, including transitive and nested packages, so you see the true scope of impact before taking action.
ActiveState’s VMaaS solution delivers the last mile of vulnerability management through risk prioritization, precision remediation, and expert guidance. Here’s why it’s important to your enterprise cybersecurity strategy.
Open source powers everything. Our latest report provides a candid look into how organizations manage vulnerabilities and remediation, and why traditional tools are no longer enough to tackle vulnerability remediation.
Does it feel like your DevSecOps teams are constantly dodging cybersecurity threats? It’s a frustrating reality for many. Explore why opting for security-as-a-service can help your team overcome these mounting challenges.
Chat with a member of our product team today.
Chat with a member of our product team today.
To provide the best experiences, we and our partners use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us and our partners to process personal data such as browsing behavior or unique IDs on this site and show (non-) personalized ads. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Click below to consent to the above or make granular choices. Your choices will be applied to this site only. You can change your settings at any time, including withdrawing your consent, by using the toggles on the Cookie Policy, or by clicking on the manage consent button at the bottom of the screen.
