Legacy Languages
The Open Source Problem That Never Goes Away
Community support ends. Vulnerabilities and compliance requirements don't.
Organizations running business-critical Perl, Tcl, and Ruby applications have faced this for years: the ecosystem moves on, security patches stop, and the operational burden lands on your security and engineering teams. That pattern is what led us to build the Curated Catalog.
.webp)
Where We Came From
ActiveState was founded on Perl. In 1997, we ported Perl, Python, and Tcl to Windows and enterprise platforms, making these languages viable for the organizations running the world's most critical systems. For decades, ActivePerl and ActiveTcl were the enterprise standard.
That history gave us 25+ years of direct experience with what it takes to keep open source languages secure, stable, and compliant inside large organizations. It's the foundation everything we build today is based on.
What We Built Instead
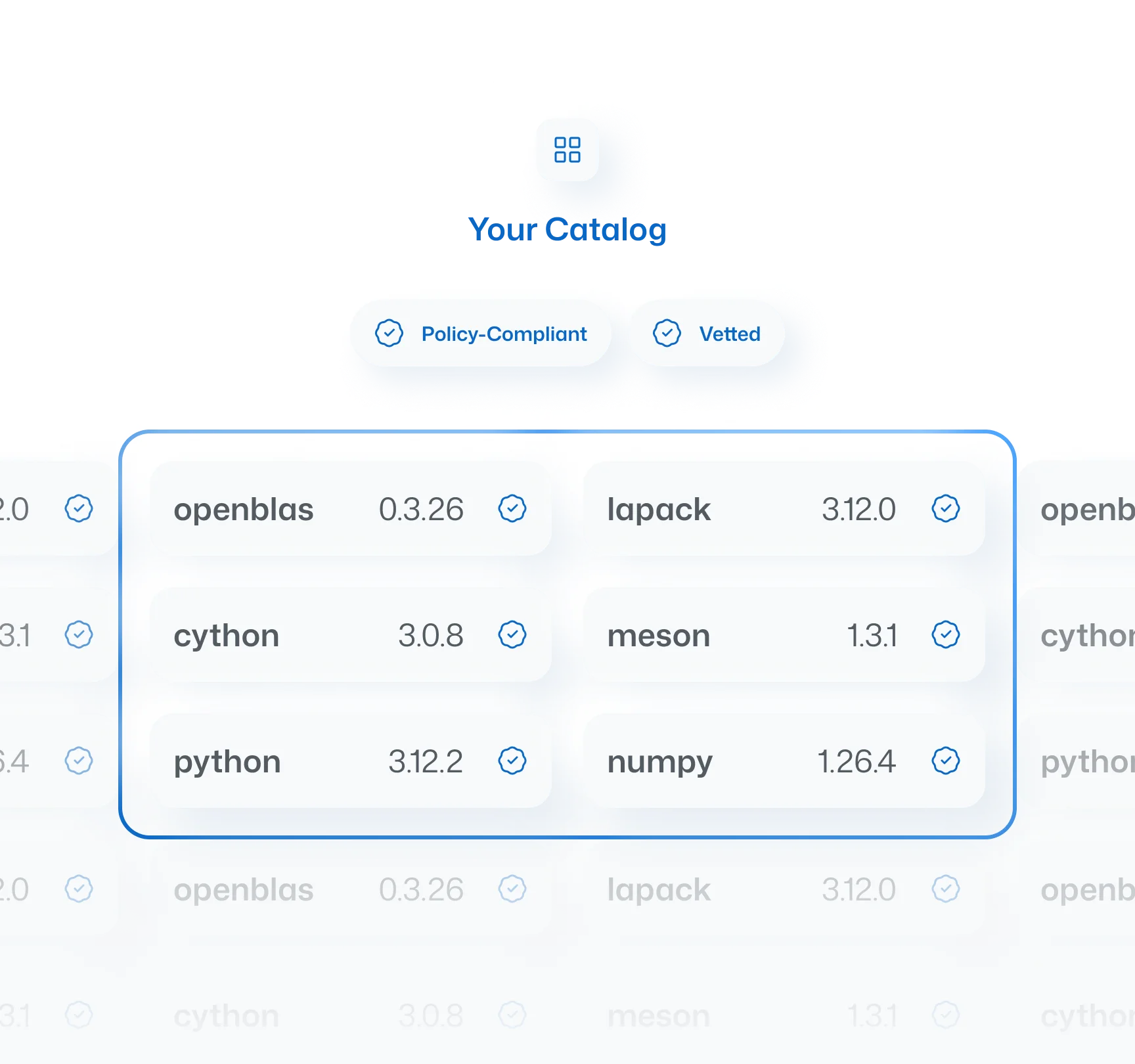
The Curated Catalog is ActiveState's answer to the open source governance problem at scale. Instead of chasing EOL dates language by language, it gives enterprise teams a single, continuously remediated source of vetted open source packages, built from source, delivered through Artifactory, Nexus, pip, Maven, and the rest of the toolchain your teams already use, across every ecosystem your organization runs.
Same commitment. Current infrastructure.
%20(1).webp)
Still Running Perl, Tcl, or Ruby?
If your organization has existing ActiveState legacy language deployments, our team can help you understand your options, including what a path toward secure open source looks like for your environment.
FAQs
Is ActiveState still an active company?
Yes. ActiveState is actively developing and selling the Curated Catalog, which secures open source software for enterprise engineering teams. Our legacy language products, ActivePerl, ActiveTcl, and ActiveRuby, represent where we started. The Curated Catalog is where we are today.
Does ActiveState still sell ActivePerl and ActiveTcl?
ActiveState continues to support existing enterprise deployments. New customers start with the Curated Catalog, which covers 9 modern ecosystems from a single governed source.
What does ActiveState do now?
ActiveState builds and operates the Curated Catalog, a continuously remediated, source-built repository of vetted open source packages delivered through the artifact repositories, package managers, and CI/CD pipelines enterprise teams already use. The focus is open source governance at scale: security, licensing, provenance, and compliance across every language ecosystem an organization runs.
How has ActiveState's product evolved?
ActiveState started by making open source languages viable for enterprise Windows environments in 1997. That work revealed a persistent problem: open source moves fast, community support ends, and enterprise security and compliance requirements don't. The Curated Catalog is the product that came out of 25+ years of solving that problem: built for the way engineering teams work today, including in AI-accelerated development environments.
Is ActiveState relevant for modern engineering teams?
Yes. ActiveState is designed for enterprise teams running AI coding tools, managing large and complex open source footprints, and operating under regulatory pressure. It addresses the open source governance challenges that have intensified as AI-generated code accelerates dependency growth and increases supply chain risk.
What problem does ActiveState solve today?
Enterprise engineering teams consume open source at a scale and speed that outpaces manual security review. AI coding tools accelerate that further. ActiveState provides a curated, continuously remediated source of vetted open source packages, so security teams govern what enters the environment, and developers keep building without friction.
Still have questions?
Talk to our team.
Keep Legacy Code Running Securely
Talk to our team about extended lifecycle support for your Perl or Tcl deployments.
%20(1).webp)