Secure Packages Through the Tools You Already Use
No more CVE triage, manual patching, or dependency archaeology. ActiveState handles open source maintenance and remediation automatically.
.webp)
%20(1).webp)
AI coding assistants stay on rails
Point GitHub Copilot, Cursor, Claude Code, or any other AI code generator at your Curated Catalog. Every suggestion pulls from vetted, policy-compliant open source packages instead of the open internet. No hallucinated dependencies, no rogue imports, no surprise licenses buried three layers deep in a transitive dependency.
Emergency dependency swaps drop, and last-minute CVEs stop killing your releases.
pip install stays pip install
Your Curated Catalog works with pip, npm, Maven, and every other major package manager. Packages arrive as native artifacts like Python Wheels, so your workflow doesn't change. Point your package manager at the Catalog instead of a public registry and you're done.
Works natively with JFrog Artifactory, Sonatype Nexus, and AWS CodeArtifact
Compatible with GitHub Packages, GitLab Package Registry, and Azure Artifacts
12 language ecosystems from a single source, including Python, Java, JavaScript, C Libraries, and R
.webp)
.webp)
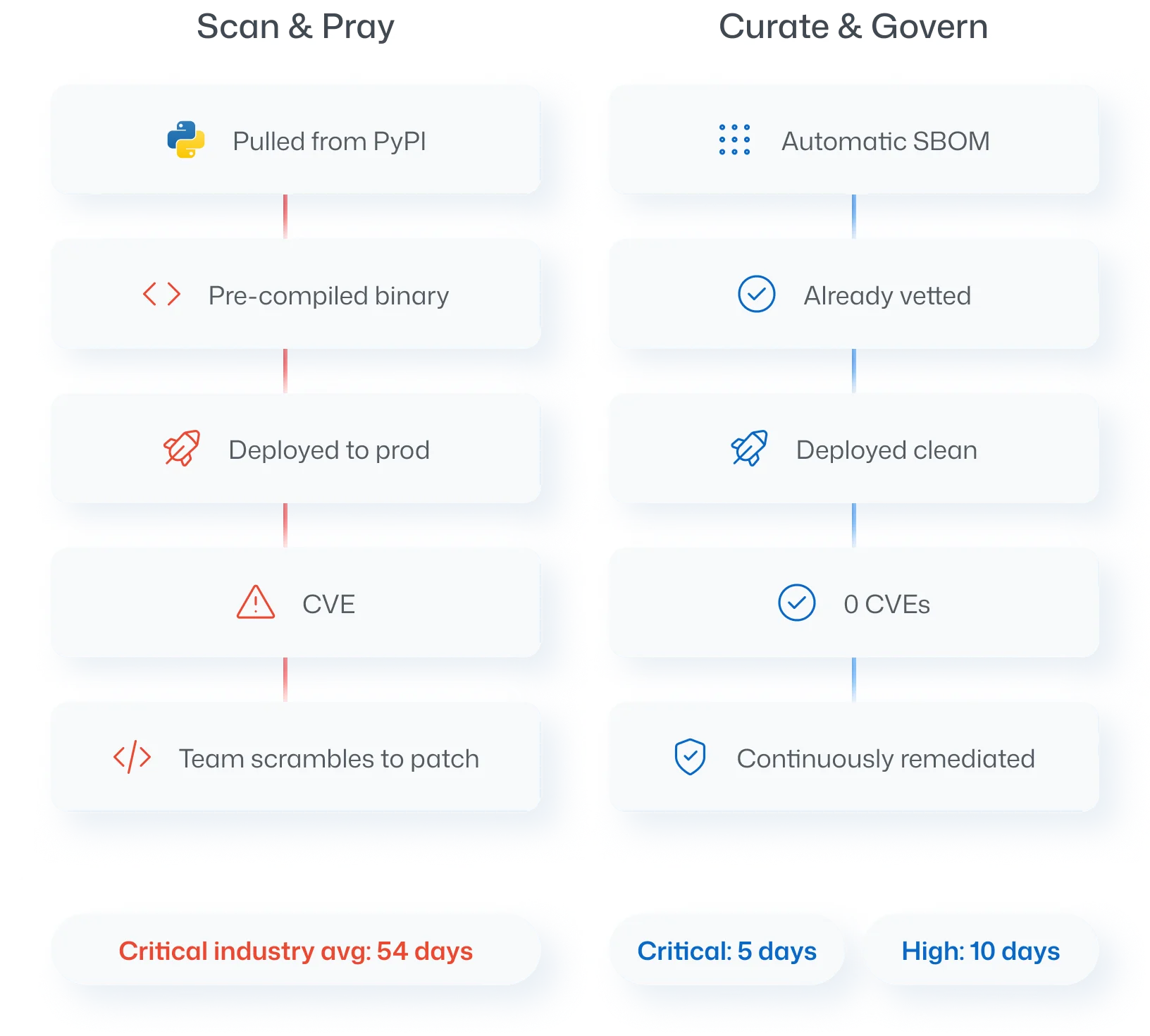
Skip the security approval queue
Every package in the catalog is pre-vetted and continuously monitored with remediation SLAs of 5 business days for Critical CVEs and 10 for Highs. Security pre-approves the source, so your dependencies are clean by the time they reach review.
No more remediation work on your plate
Python, Java, JavaScript, Go, R, C, Rust, .NET, and more. 79M+ components across 12+ ecosystems, all compiled from original source code in SLSA Level 3 infrastructure. When a vulnerability surfaces, ActiveState builds and publishes the fix. Your time goes back to product development.
FAQs
Will ActiveState slow down development velocity?
No, the opposite. Packages are pre-approved, so you skip security holds and manual CVE cleanup. Same install command, fewer blockers.
What languages does ActiveState's Curated Catalog support?
ActiveState supports 12 languages, including Python, Java, Javascript and more.
Do I need to install new tooling with ActiveState?
No. ActiveState delivers packages through the package managers, artifact repositories, and CI/CD pipelines you already use. No new CLI, no plugins, no setup.
Can I pin specific versions?
Yes. You define exact versions per project. ActiveState resolves all dependencies against your pinned versions and delivers a consistent build every time.
Still have questions?
Talk to our team.
See how easy secure open source can be
Book a walkthrough and we'll show you how the ActiveState Curated Catalog fits your stack. No new tools, no workflow changes.
%20(1).webp)