
Download and install the pre-built Recommendation Engine runtime or automatically build your own custom Python runtime on the ActiveState Platform
To provide insight into how recommendation engines are designed from a coding perspective, this tutorial will demonstrate how to build a simple recommendation engine in Python. The engine analyzes data from previous purchases to help identify items that are typically bought together. In doing so, it will provide functionality that can be leveraged to endorse relevant products when a particular product is selected.
All code and data for the sample recommendation engine can be found in my GitHub repository.
If you spend any amount of time shopping online, streaming music or streaming video, it’s highly likely that you’ve encountered a recommendation engine. As the term indicates, a recommendation engine is a service that makes recommendations to a user, typically based on:
- The user’s specific behaviour
- Similar behaviour by other users
- An algorithm that predicts the user’s most likely future behaviour
In the realm of streaming music, a recommendation engine might provide a list of similar songs or albums that align with the user’s listening preferences to date. The recommendation could be based on a number of variables, including songs and albums the user has previously listened to, user-rating data for music in genres they tend to seek out, etc. Recommendations from this kind of service can connect users to the type of music they prefer, in a fast, efficient manner. And if the recommendations are frequently accepted, it can help make the streaming music service more sticky with users.
Also popular is the use of recommendation engines by e-commerce platforms. Have you ever purchased an item from an online store and had additional items identified by the system as those you may also be interested in buying? If so, then you’ve encountered a purchase recommendation engine.
Recommendation Engine in Python: Installing Python
For this tutorial you can use ActiveState’s Python, which is built from vetted source code and regularly maintained for security clearance. For ActivePython, you have two choices:
- Download and install the pre-built Recommendation Engine runtime environment for Windows 10, macOS, CentOS 7, or…
- Build your own custom Python runtime with just the packages you’ll need for this project, by creating a free ActiveState Platform account, after which you will see the following image:
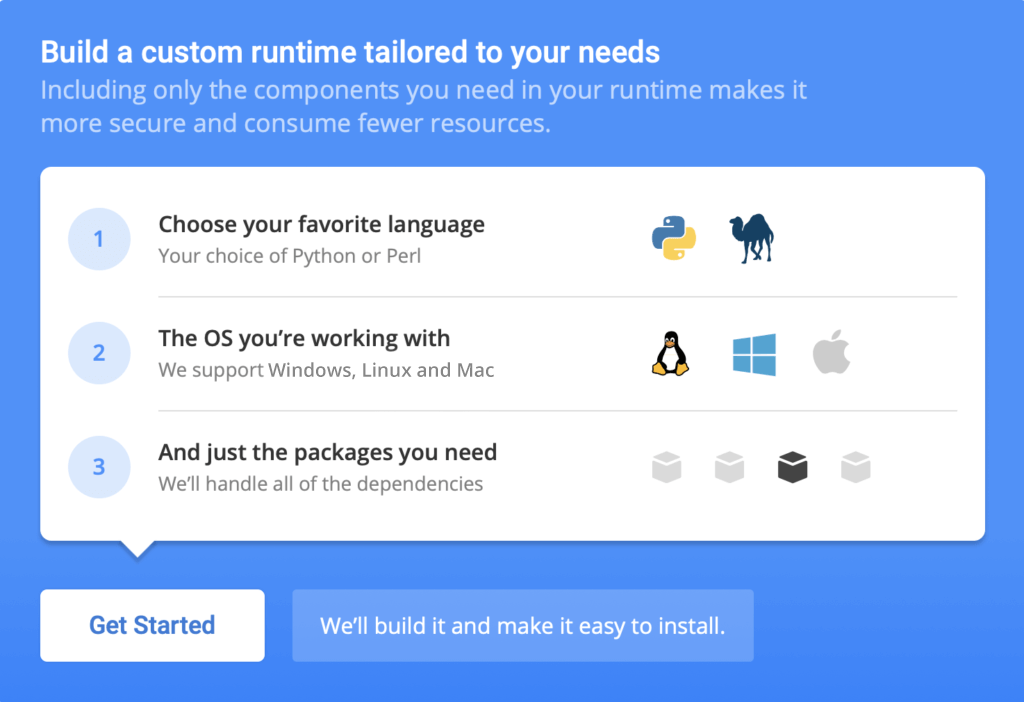
- Click the Get Started button and choose Python 3.7 and the OS you’re working in. Choose the packages you’ll need for this tutorial, including:
- Pandas – a data analytics library used for the manipulation and analysis of the datasets that will drive our recommendation system
- Flask – a microservices framework used for exposing our recommendation engine via a REST API
- Once the runtime builds, you can download the State Tool and use it to install your runtime.
And that’s it! You now have Python installed in an easy-to-deploy virtual environment that has all your dependencies resolved for you, as well as everything you need to build the sample application. In doing so, ActiveState takes the (sometimes frustrating) environment setup portion out of your hands, allowing you to focus on actual development.
Recommendation Engine in Python: Data
A recommendation engine is only as “intelligent” as the data allows. In our particular system, we’ll be identifying products that are frequently bought with the selected item in order to recommend the shopper also purchase additional, relevant products. To do so, we will read data from two sources:
- Product.csv
- OrderProduct.csv
The Product.csv dataset has two columns: product_id and name. The data are exactly what they sound like, simply an ID value associated with the name of the product.
In OrderProduct.csv, there are also two columns: order_id and product_id. Each row is a unique combination of these two properties. Consider the below snippet from OrderProduct.csv (the full file can be found as part of the GitHub repository for this project):
| order_id | product_id |
| 1 | 1 |
| 1 | 2 |
| 2 | 3 |
| 2 | 10 |
| 2 | 13 |
In essence, the order with ID 1 is made up of products with ID values 1 and 2. While the order with ID 2 is made up of products with ID values 3, 10 and 13.
The actual products are listed in Product.csv:
| product_id | product_name |
| 1 | Baseball Bat |
| 2 | Baseball Glove |
| 3 | Football |
| 4 | Basketball Hoop |
| 5 | Football Helmet |
| 6 | Batting Gloves |
| 7 | Baseball |
| 8 | Hockey Stick |
| 9 | Ice Skates |
| 10 | Soccer Ball |
| 11 | Goalie Mask |
| 12 | Hockey Puck |
| 13 | Cleats |
Recommendation Engine in Python: Code
Now that we know what we’re working with data-wise, let’s get into implementing the actual recommendation service. In this example, the engine itself will be made up of a single function located within a Python module named engine.py.
At the top of the engine.py module, we first import the Pandas library for reading and manipulating our datasets:
import pandas as pd
Next, we define a function with one parameter representing a product ID value. It is based on this product ID that we’ll analyze the datasets. Our goal is to find the products typically purchased in conjunction with the product represented by the provided ID:
def get_recommendations(id):
Within this function is where the real work is done. The first step is to use Pandas to read in the OrderProduct dataset, and then filter the data to retrieve only rows where the product ID is equal to the ID passed to the function. Breaking it down a little further, we grab the unique order IDs where the product passed into the function was part of the order:
orders = pd.read_csv(“data/OrderProduct.csv”) orders_for_product = orders[orders.product_id == id].order_id.unique()
With the applicable order IDs, it becomes a straightforward process to get all rows in OrderProduct.csv, excluding those for the product that was passed in. This represents all OrderProduct instances of items bought in conjunction with the product by product ID:
relevant_orders = orders[orders.order_id.isin(orders_for_product)] accompanying_products_by_order = relevant_orders[relevant_orders.product_id != id]
The next step is to manipulate the data a little more by getting the numeric value representing the number of instances in which these additional products were purchased. We can do so using Pandas:
num_instance_by_accompanying_product = accompanying_products_by_order.groupby(“product_id”)[“product_id”].count().reset_index(name=“instances”)
To give some perspective on what this looks like, let’s consider the output from passing the value 3 (as the product ID) to this function. Keep in mind that product ID 3 represents a football, so what we expect is the data to tell us which products have previously been bought in conjunction with a football.
| product_id | instances | |
| 0 | 5 | 2 |
| 1 | 7 | 1 |
| 2 | 10 | 1 |
| 3 | 12 | 1 |
| 4 | 13 | 4 |
The above output indicates that:
- A baseball (product id 7), a soccer ball (id 10) and a hockey puck (id 12) were purchased in conjunction with a football once.
- A football helmet (id 5) was purchased twice in conjunction with a football.
- Cleats (id 13) were purchased four times in conjunction with a football.
So we can roughly conclude that (in this small sample set) cleats and a football helmet are the most popular purchases made along with a football.
The next step is to calculate the percentage at which these items are bought in conjunction with the product passed to the function, and append this column to the representation displayed above. From here, we can create a new Pandas DataFrame that takes the top three results by frequency. This DataFrame will represent the three items most frequently bought with the selected product. Finally, we read in Product.csv and join this to our top three recommendations DataFrame on the product ID column. This allows us to include the product names for our top three results, as well:
num_orders_for_product = orders_for_product.size
product_instances = pd.DataFrame(num_instance_by_accompanying_product)
product_instances["frequency"] = product_instances["instances"]/num_orders_for_product
recommended_products = pd.DataFrame(product_instances.sort_values("frequency", ascending=False).head(3))
products = pd.read_csv("data/Product.csv")
recommended_products = pd.merge(recommended_products, products, on="product_id")
After this is complete, the last line of our function simply returns the top three results in JSON format:
return recommended_products.to_json(orient="table")
Recommendation Engine REST API
Making our recommendation system available via a reusable service endpoint has significant value, since it can then be leveraged across multiple platforms to increase its value to the organization. Using Flask, we can take the above example and build a simple API method that allows us to retrieve the JSON-formatted response with ease. Let’s take a look at the code that we’ll store in a Python module named app.py:
from flask import Flask
import engine
app = Flask(__name__)
@app.route("/api/v1.0/recommendations/<int:id>", methods=["GET"])
def get_recomendations(id):
print("product_id: " + str(id))
return engine.get_recommendations(id)
if __name__ == "__main__":
app.run()
Testing the code is fairly straightforward; simply navigate to the directory in which app.py is located, and run the following command:
python app.py
Next, open a web browser and navigate to the following URL (our API endpoint):
http://localhost:5000/api/v1.0/recommendations/3
This should return a JSON-formatted response representing the top three products typically bought with a football:

The Value of a Recommendation Engine
Recommendation engines can provide significant value to the user-base for virtually any type of business. And while the statistical algorithm for determining a particular set of recommendations may be complex, the concepts behind implementing such a system are relatively straightforward. With the right tools, such as Python and Pandas, datasets can be analyzed efficiently and effectively to glean valuable insights in an effort to provide relevant recommendations to the customer.
They also offer tremendous ROI for businesses:
- 70% of all the Netflix movies a user watches is a personalized recommendation
- 35% of consumer purchases on Amazon come from product recommendations (McKinsey estimate)
- On Single’s day in China (Nov 11, 2016), Alibaba vendors experienced a 20% conversion rate improvement on pages that displayed product recommendations
Industries from food to sports to fashion are using recommendation engines to provide customers with a more complete buying experience, and generating more loyal customers because of it.
Next Steps
- All code and data can be found in my GitHub repository
- Download and install the pre-built Recommendation Engine runtime or or automatically build your own custom Python runtime on the ActiveState Platform
Related Blogs:



