
NLTK and spaCy are two of the most popular Natural Language Processing (NLP) tools available in Python. You can build chatbots, automatic summarizers, and entity extraction engines with either of these libraries. While both can theoretically accomplish any NLP task, each one excels in certain scenarios. First, I’ll provide some background about how NLTK and spaCy differ in general, and then I’ll dive into how each library handles specific tasks.
Natural Language Processing: History
There’s a real philosophical difference between NLTK and spaCy. NLTK was built by scholars and researchers as a tool to help you create complex NLP functions. It almost acts as a toolbox of NLP algorithms. In contrast, spaCy is similar to a service: it helps you get specific tasks done.
Due to this difference, NLTK and spaCy are better suited for different types of developers. For scholars and researchers who want to build something from the ground up or provide a functioning model of their thesis, NLTK is the way to go. Its modules are easy to build on and it doesn’t really abstract away any functionality. After all, NLTK was created to support education and help students explore ideas.
SpaCy, on the other hand, is the way to go for app developers. While NLTK provides access to many algorithms to get something done, spaCy provides the best way to do it. It provides the fastest and most accurate syntactic analysis of any NLP library released to date. It also offers access to larger word vectors that are easier to customize. For an app builder mindset that prioritizes getting features done, spaCy would be the better choice.
Approach and Performance
A core difference between NLTK and spaCy stems from the way in which these libraries were built. NLTK is essentially a string processing library, where each function takes strings as input and returns a processed string. Though this seems like a simple way to use the library, in practice, you’ll often find yourself going back to the documentation to discover new functions.
In contrast, spaCy takes an object-oriented approach. Each function returns objects instead of strings or arrays. This allows for easy exploration of the tool. Developers don’t need to constantly check with documentation to understand context because the object itself provides it.
Each library utilizes either time or space to improve performance. While NLTK returns results much slower than spaCy (spaCy is a memory hog!), spaCy’s performance is attributed to the fact that it was written in Cython from the ground up.
Most sources on the Internet mention that spaCy only supports the English language, but these articles were written a few years ago. Since then, spaCy has grown to support over 50 languages. Both spaCy and NLTK support English, German, French, Spanish, Portuguese, Italian, Dutch, and Greek.
Installation
Before we dive in and take a look at the code level differences between NLTK and spaCy, you’ll need to install Python if you want to follow along with this tutorial. If you don’t have a recent version of Python, I recommend doing one of the following:
- Download and install the pre-built NLP Comparison runtime environment for Win10 or CentOS 7; or
- If you’re on a different OS, you can automatically build your own custom Python runtime with just the packages you’ll need for this project by creating a free ActiveState Platform account, after which you will see the following image:
- Click the Get Started button and choose Python and the OS you’re comfortable working in. Choose the packages you’ll need for this tutorial, including NLTK and spaCy.
- Once the runtime builds, you can either download it directly, or else download the State Tool CLI and use it to install your runtime.
And that’s it! You now have installed Python in a virtual environment. You can also find all the code in this post in my GitHub repository.
Natural Language Processing with NLTK and Spacy
To get started, create a new file like nlptest.py and import our libraries:
# NLTK import nltk # spaCy import spacy nlp = spacy.load(“en”)
Tokenization
In the natural language processing domain, the term tokenization means to split a sentence or paragraph into its constituent words. Here’s how it’s performed with NLTK:

And here’s how to perform tokenization with spaCy:

Parts Of Speech (POS) Tagging
With POS tagging, each word in a phrase is tagged with the appropriate part of speech. Since words change their POS tag with context, there’s been a lot of research in this field.
Here’s what POS tagging looks like in NLTK:

And here’s how POS tagging works with spaCy:

You can see how useful spaCy’s object oriented approach is at this stage. Instead of an array of objects, spaCy returns an object that carries information about POS, tags, and more.
Entity Detection
Now that we’ve extracted the POS tag of a word, we can move on to tagging it with an entity. An entity can be anything from a geographical location to a person’s name to even pieces of furniture!
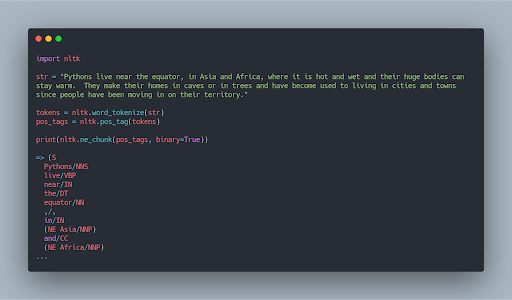
With NLTK, entity extraction has great support right out of the box:
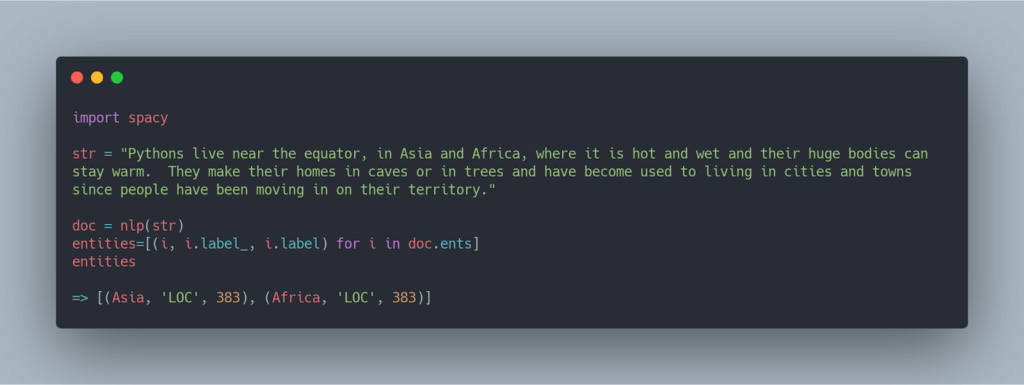
With spaCy, entity extraction is handled in the following manner:
Conclusions
Both NLTK and spaCy offer great options when you need to build an NLP system. As we have seen, however, spaCy is the right tool to use in a production environment. Its underlying philosophy – providing a service rather than being a tool – is behind its extreme user-friendliness and performance. spaCy just gets the job done!
- You can find all the code in this post in my GitHub repository
- Download and install the pre-built NLP Comparison runtime environment for Win10 or CentOS 7, or automatically build your own custom Python runtime on the ActiveState Platform
Related Blogs:
Frequently Asked Questions
What are spaCy and NLTK used for?
For more information on other NLP libraries in Python, see BERT vs ERNIE: The Natural Language Processing Revolution.
Which language is best for natural language processing?
For more information on cutting-edge NLP libraries in Python, refer to the article BERT vs ERNIE: The Natural Language Processing Revolution.
What are the most popular Python libraries used for NLP?
- NLTK – one of the original Python libraries for NLP, and still a popular choice
- spaCy – great for programmers that want to include NLP features in their applications
- Bert – or Bidirectional Encoder Representations from Transformers was developed by the Google AI Language Team.
- Ernie – or Enhanced Representation through kNowledge IntEgration was developed by Google’s Chinese competitor, Baidu.
Get the pre-built NLP Comparison Python environment, which includes spaCy and NLTK so you can get started right away.
What is the difference between spaCy and NLTK?
SpaCy, on the other hand, provides fast and accurate syntactic analyses, as well as access to larger word vectors that are easier to customize. For developers building applications, spaCy would be the better choice.
Try both spaCy and NLTK. Get the pre-built natural language processing (NLP) Python environment with both packages installed, so you can experiment right away.



