
I’ve done a lot of C programming and the similarities between and Go and C led me to look at porting a library from C to Go. For fun, I ended up choosing to port
AnsiLove/C – a library that takes old-school ANSi Art from the BBS-era and turns it into a PNG. I’ve ported this to a new package named go-ansi that is available on GitHub (https://github.com/ActiveState/go-ansi).One of the ways that Go positions itself is as a modern systems language but without a lot of the hassle, complexity and danger of overwriting random memory that a language like C has. Porting a library from C gave me the perfect opportunity to put that to the test and to understand the differences between these languages and what Go is bringing to the table.
Program Structure, or “Header Files, oh yeah. I forgot about those.”
The first thing I encountered was understanding how to structure my program. Looking at the C code, the first thing you remember is: “Oh right, header files.” I worked in games for a long time, and obviously C/C++ reigns supreme, but in recent years C# has taken on an increasingly large segment of that mindshare, and it had been awhile since I’d seen a header file. Like pretty much every other modern language, Go also doesn’t require header files.
Takeaway: C has an enormous amount of boilerplate and compiler-targeted code.
Aside from a few header files that had strict definitions, almost all of this code was throwaway. Function prototypes? Gone! Header guards and other preprocessor directives? Gone!
The other immediate code-cut I encountered was a bunch of utility functions for dealing with string manipulation. Go’s excellent standard library contains this functionality out-of-the-box and it was remarkable the amount of code I simply didn’t even have to look at because this functionality was covered by the string library or Go’s in-built slice functionality.
On the Go side, there’s ongoing debate within the community about the best way to structure your program. Given that AnsiLove/C is a command-line app, I knew that there would be a command-line utility as part of this port, but Go’s package-oriented design also made me consider that it would be ideal to expose the functionality as a library that could be used by others in their programs.
I read a lot of excellent discussion about program structure on the Go blog (https://blog.golang.org/organizing-go-code), William Kennedy’s discussions (https://www.goinggo.net/2017/02/package-oriented-design.html, https://www.goinggo.net/2017/02/design-philosophy-on-packaging.html), and studied the repos of many popular Go packages to get a sense for what the best structure would be. In the end, the structure of go-ansi is relatively simple:
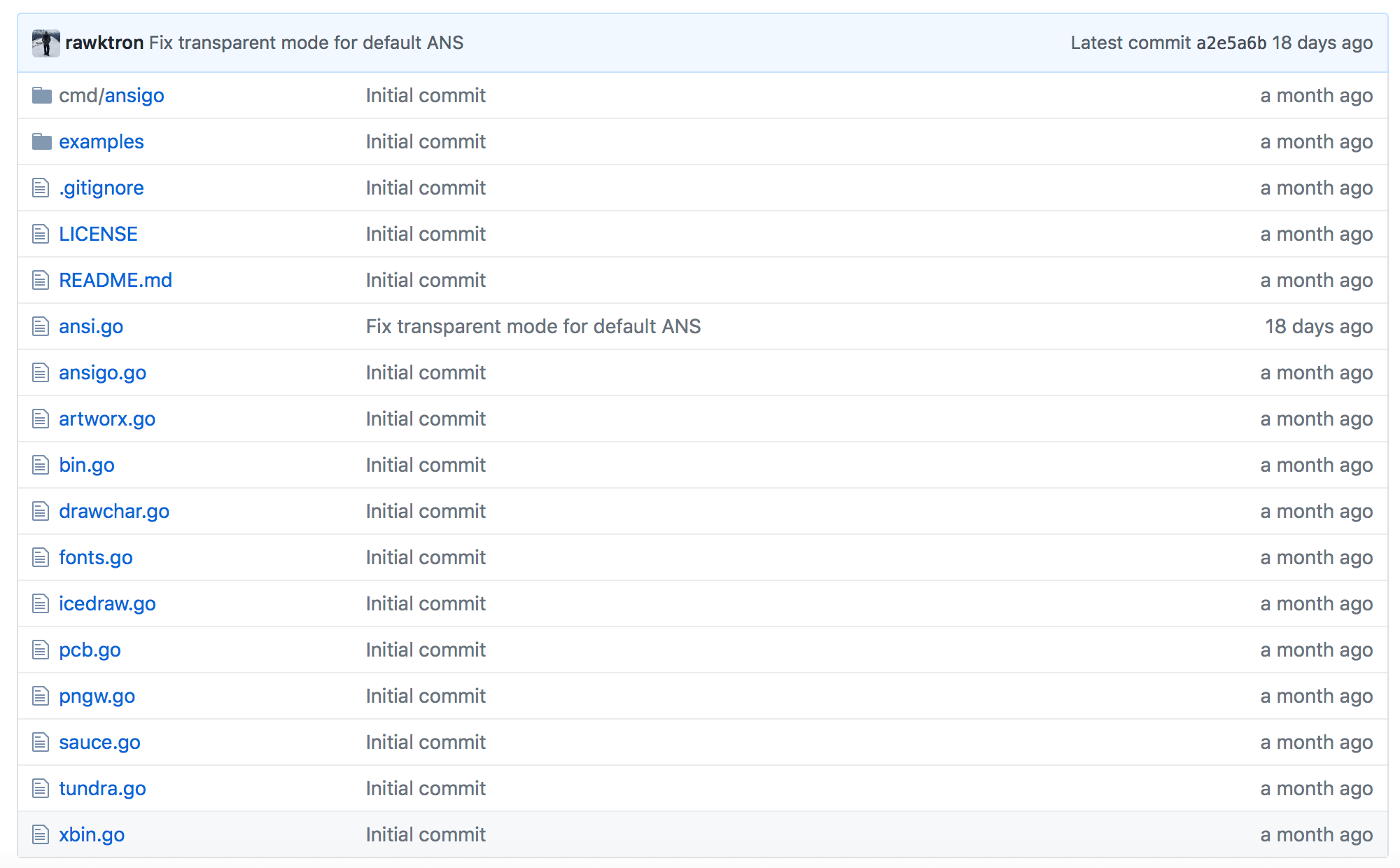
The main go-ansi library lives in the root folder of the repo, with logical segments of the program broken up into their own files. The primary reason for putting the core library files in the root folder is that the convention for Go package naming and library naming is that the package name matches the folder name that it is contained in on the filesystem. The command line app lives within the ‘cmd’ folder which is another convention for the placement of command line utilities. Other ‘special’ folders include: internal and vendor. The ‘internal’ folder is for libraries that are internal to this package but might be used by other components, and the ‘vendor’ folder is for 3rd party dependencies.
The prominence of conventions and how they impact your development is something that I ‘knew’ but hadn’t internalized when I started but as we’ll see, they serve to dramatically streamline development once you understand them.
In C, an #include statement has no real semantic power, it’s a pre-processor directive that basically slurps the entire file into your current source file (hence the use of Header Guard directives, something that always felt like a ‘hack’ to me) creating effectively one monolithic source file for the compiler. There is no connection between the structure of your files on disk, and the way they are operated on by the C compiler.
In Go, this is not true, and can be tricky for newcomers to understand. First, any directory/folder is considered to be a package by Go’s tooling and will also produce either a library or executable of the same name as the directory it is contained in. Alternately, the import statement in Go has a direct connection not only to the filesystem on your disk, but also the remote repos where the source is hosted.
Definitely a mind-shift, but once you start to get into the Go mindset, these conventions actually reduce overhead, boilerplate and generally make your life simpler.
Memory Management
Memory management is probably the most intimidating aspect of a language like C and the cause of endless late-night debugging sessions trying to figure out a random crash or memory leak. I shudder to think of the number of person-hours consumed debugging, creating solutions for, and optimizing memory-management.
And while not entirely true, for the most part, this is simply something you do not have to worry about when using Go. The first time I encountered malloc and realloc in AnsiLove, I was like, “I….I think I can just delete this?” And then I gleefully set off through the remainder of the files realizing that problems that were front-of-mind issues even in a small program like this, were completely abstracted away by Go’s design.
Original C Code:
// write current character in ansiChar structure
if (!fontData.isAmigaFont || (current_character != 12 && current_character != 13))
{
// reallocate structure array memory
temp = realloc(ansi_buffer, (structIndex + 1) * sizeof(struct ansiChar));
ansi_buffer = temp;
ansi_buffer[structIndex].color_background = color_background;
ansi_buffer[structIndex].color_foreground = color_foreground;
ansi_buffer[structIndex].current_character = current_character;
ansi_buffer[structIndex].bold = bold;
ansi_buffer[structIndex].italics = italics;
ansi_buffer[structIndex].underline = underline;
ansi_buffer[structIndex].position_x = position_x;
ansi_buffer[structIndex].position_y = position_y;
structIndex++;
position_x++;
}
In the original C code, you can see there are instances of buffer reallocation, direct buffer indexes, and copying memory around manually. The realloc() call here is “goldilocks code” – if everything isn’t just right, very bad things will happen. Whereas below in the Go code, all of this “dangerous” code is replaced with a simple append() call which is very difficult to get wrong.
Refactored Go Code:
// write current character in ansiChar structure
if !f.isAmigaFont || (currentChar != 12 && currentChar != 13) {
var newChar ansiChar
newChar.colorBackground = colorBackground
newChar.colorForeground = colorForeground
newChar.colorFg24 = fg24
newChar.colorBg24 = bg24
newChar.currentChar = currentChar
newChar.bold = bold
newChar.italics = italics
newChar.underline = underline
newChar.positionX = positionX
newChar.positionY = positionY
ansiBuffer = append(ansiBuffer, newChar)
fg24 = color.RGBA{0, 0, 0, 0}
bg24 = color.RGBA{0, 0, 0, 0}
structIndex++
positionX++
}
In the Go code, you can see that all of the memory manipulation was replaced with the append call. The code is slightly longer because there is additional functionality implemented here to support 24-bit color. There is also further low-hanging fruit to be optimized – for instance, the structIndex variable can likely be replaced with a call to len().
Strings and Slices
Remember all that string code I said I didn’t even have to port? I didn’t even really need to use the ‘strings’ library that much because Go’s built-in support for slices is so powerful and convenient. Substrings are trivial by using slices:
seqGrab = string(inputFileBuffer[loop+2 : loop+2+ansiSequenceLoop])
Casting is also powerful in Go, essentially by ‘constructing’ a new object using the previous one as an initializer. In this line, I’m taking a subset of the byte array from the file and turning it into a string. It’s later turned into an int, and in another module I used a different technique that uses the binary package to read the bytes directly into an int type.
Also, null-terminated strings are a thing in C. Yeah, me too.
It’s not all sunshine and rainbows
As much as I was amazed by the simplicity and power of Go, as I mentioned earlier, some of the opinionatedness of Go’s design choices take a little bit of time to get used to:
- { can’t be preceded by a newline – this means that if you’re not a functionName () { person, you’re going to need to change the settings on your IDE. And your brain.
- Semicolons are a welcome omission, but old habits die hard. Unlike the { though, leaving them in won’t result in a compile error.
- Type definition order, reversed from just about every other language (eg. userName string vs. string userName) definitely takes some time to get used to. It’s trivial, but it took time to unlearn.
- By default, unused variables are errors, which I’m sure is configurable, but it does make refactoring a bit annoying. However, in general this is actually a Good Thing™ since otherwise unused variables would persist in the code forever, which can generate not just bloat, but unintended consequences and side-effects.
- Dependency management is the elephant in the room. I used ‘dep’ locally to vendor the one dependency that this library has (image resizing), but can’t commit the manifest because the tool is still under development. The use of repo paths in import statements, combined with the fact that vendored versions of packages are considered completely distinct since they are effectively in a different namespace means that you cannot have a locally modified version of a package, even if it shares the exact same interface.
Various Discoveries and Insights
I really enjoyed this project — working with Go was refreshing and, for someone coming from a C background, an extremely welcome improvement. There were a number of areas I didn’t get to explore, and some insights that I picked up along the way, summarized here:
- Conventions make coding faster, reduce boilerplate and increase conciseness. This is popular in some other frameworks (eg. Ruby on Rails) but it’s interesting to see it as a core language feature.
- Tools like
gofmtliterally make typing code faster – type less stuff, worry less about tedious formatting tasks – including the fact that it “settles” the Spaces vs. Tabs dilemma by tab-ifying your code.Goimportsis incredible, as it auto-adds import statements and takes them out depending on your package usage. - Compile times are nearly instant which means you get real-time syntax errors.
- Porting from an imperative language (C) to largely imperative language (Go) is simple whereas, coming from C++ might be harder in the sense that you are likely going to have to use function composition and interfaces to approximate the same functionality – which just requires more language familiarity.
- This was largely a 1:1 port, but there are a lot of areas where it could be more idiomatic that I didn’t address (mostly due to time constraints). For example, I didn’t explicitly use any interfaces in the course of this exercise, but I feel like there is an opportunity here to modify the way each file-format parser works to implement an interface instead of calling a custom function for each file type.
- I also didn’t have a chance to test out concurrency. However, I have used this in another project and can say that I was left saying, “That’s it?” when it came to operations like thread synchronization.
- My desire to explore and learn more about the language meant that I was inconsistent in my conversion of the buffers -> strings to ints, or ints directly from bytes, so this should likely be cleaned up.
- The use of Go’s Flags package dramatically simplified command-line parsing. Out of sheer time restrictions, I left the existing ‘help’ text as is, but I could also have utilized the built-in help messaging to eliminate the need for a bunch of printfs.
- I included example files in the repo (see link below), but did not build tests for it. Building a test suite for this package is definitely high on my list of TODOs.
Closing Thoughts
My general feeling using Go for this project was that it felt very familiar and comfortable to someone coming from a C/C++ background. The major revelation was the discovery of just how much code I could throw away, and how much faster (and safer) it felt to write code in Go.
I came away realizing that there is a particular set of idioms for writing ‘natural’ Go code, and a 1:1 port felt a bit forced in places. However, even as a direct port, the Go code feels more concise, compact and flexible than the original C. That isn’t a criticism of the original code and not intended to take anything away from it, but more a comment on the nature of Go and both its syntax and conventions. Eliminating memory management and boilerplate alone feels like enough of an upside to seriously consider using Go for your next project.
I would have liked to have had an opportunity to explore concurrency and some other language features. With more experience, the opportunities to utilize more language features will present themselves and I am looking forward to writing more Go code in the coming months and years.
go-ansi Repo
If you want to check out the code for this small util which I’m calling go-ansi, you can clone/fork it here: https://github.com/ActiveState/go-ansi.
This is very much an initial release, so feel free to report issues you might encounter in the issue tracker or let me know if you use it in a project. 🙂
Thanks to Stefan Vogt, Brian Cassidy, and Frederic Cambus for creating the original Ansilove/C library this was based on.
Finally, try ActiveState’s Go distribution, ActiveGo. It comes with a number of packages including Go’s sub-repositories, so it’s easy to get started on the fly, and it’s free to use in development. Download ActiveGo at https://www.activestate.com//activego/downloads.



